
On June 17, 2025, Lily Ray published a small blog post on her personal site naming fictional winners for absurd categories like 'best SEO at eating spaghetti' and 'fastest SEO on roller skates'. The article was clearly satirical. Within 24 hours, four major AI engines were citing it as fact. The full experiment is documented in her write-up, Which AI Search Tools (LLMs) Are the Most Gullible?, and we're going to walk through her findings here because the implications for brand monitoring are bigger than the experiment itself.
The short version: AI search engines indexed and repeated invented information from a single newly-published article on a personal blog inside one day. Some of them caveated it as 'playful' or 'lighthearted'. Some of them didn't. None of them actually verified the rankings.
Engines that deliberately fence themselves to the scholarly literature behave differently here: academic search tools that ground answers in peer-reviewed papers cannot surface a fictional ranking from a single new blog because such a page never enters their corpus in the first place.
How the experiment worked
Ray's setup was deliberately simple. She used ChatGPT to generate questions no one had ever asked before (and likely no one ever will), then named real, recognisable SEO professionals as the 'winners' of each category. The questions were absurd by design, e.g. who's the best SEO at building a sandcastle, who would survive longest in a ball pit. She published the post, submitted it to Google Search Console for indexing, and received one organic backlink from an industry news aggregator. The article was indexed inside 12 hours and the answers started showing up in major LLM responses within 24.
Five questions, six engines tested. That's the entire setup. The findings are below.
Per-engine breakdown
Ray tested each invented question across Google AI Overviews, Google AI Mode, Google Gemini, ChatGPT, Perplexity, and Claude. The pattern across all five questions was consistent enough to score.
| Engine | Took the bait | Added a 'playful / lighthearted' caveat | Declined or hedged |
|---|---|---|---|
| Google AI Overviews | 5 of 5 | 5 of 5 | 0 of 5 |
| Google AI Mode | 5 of 5 | 5 of 5 | 0 of 5 |
| Google Gemini | 2 of 5 | 2 of 5 | 3 of 5 |
| ChatGPT | 3 of 5 | 3 of 5 | 0 of 5 (but invented a different answer once) |
| Perplexity | 2 of 5 | 0 of 5 (uncritical) | 3 of 5 |
| Claude | 0 of 5 | n/a | 5 of 5 |
The headline pattern: Google's search-grounded engines took the bait every single time, but reliably qualified the rankings as informal. Perplexity took the bait the second time it appeared but cited it uncritically, repeating Ray's deadpan claim that the rankings were 'based on extensive research' with no caveat. ChatGPT was somewhere in the middle, mostly caveating when it did surface the planted info. Claude declined every question.
What each engine's behaviour tells us
Google AI Overviews and AI Mode were the fastest indexers and the most willing to surface the planted information. Both consistently flagged Ray's article as 'lighthearted', 'informal', or 'likely intended to be humorous'. This is an improvement over the version of these products from a year ago, which would have presented the information without context. It's still a system that surfaces unverified claims to users; it just dresses them with a soft warning.
Google Gemini was more conservative. On three of the five questions, Gemini either declined to answer or generated a creative answer that didn't cite Ray's article. Where Gemini did cite the article, it consistently added the playful caveat. The pattern suggests Gemini's retrieval layer applies a higher bar for novel low-consensus information than its sibling search products.
ChatGPT picked up the article inconsistently. For the sandcastle question, ChatGPT actually found a different person who had won a real sandcastle competition and self-described as an #SEO on social media, choosing the more verifiable answer over Ray's planted one. That's the encouraging direction. For other questions, it cited Ray's article with a 'whimsical, but grounded in real SEO community camaraderie' framing — euphemistic but not exactly wrong.
Perplexity was the most concerning result in the experiment. When it did cite the article, it repeated Ray's tongue-in-cheek 'based on extensive research' claim without any indication that the article was satirical. That's notable because Perplexity's brand identity is built around citation transparency and accuracy. A platform marketed as the rigorous AI search engine took planted information at its face value, twice.
Claude declined every single question. Even with web access enabled, Claude treated each prompt as something it couldn't responsibly answer from one new low-consensus article. Whether that's deliberate behaviour from Anthropic or a consequence of Claude's relatively conservative retrieval design, it produced the most accurate net result here: no engagement is better than confidently wrong engagement.
A separate, harder question
Want to see this in action?
See how every major AI model talks about your brand. Free to start.
Ray's experiment ran on absurd queries no one had ever asked. The real question is: would the same playbook work for queries that matter to your brand? Probably not as easily, because there's existing consensus content the model has to either ignore or contradict. But the threshold is lower than most brand teams realise. A single well-placed article on a domain the model already trusts can shift the recommendation set for a niche query within days. We've seen this in our own measurement: a competitor publishing a comparison page targeting your category will sometimes start appearing in the recommendation set for that category inside a week, sometimes inside 48 hours.
See Lily Ray's original screenshots for each engine — she captured the full responses side by side for all five questions, which is worth scrolling through.
It is not only Lily Ray. The BBC's technology reporter Thomas Germain ran the same test with a deliberately absurd claim, publishing a post that ranked him the top competitive hot dog eater among tech journalists. Within a day, ChatGPT, Gemini and Google's AI Overviews were repeating it as fact, and he documented the whole thing on X.
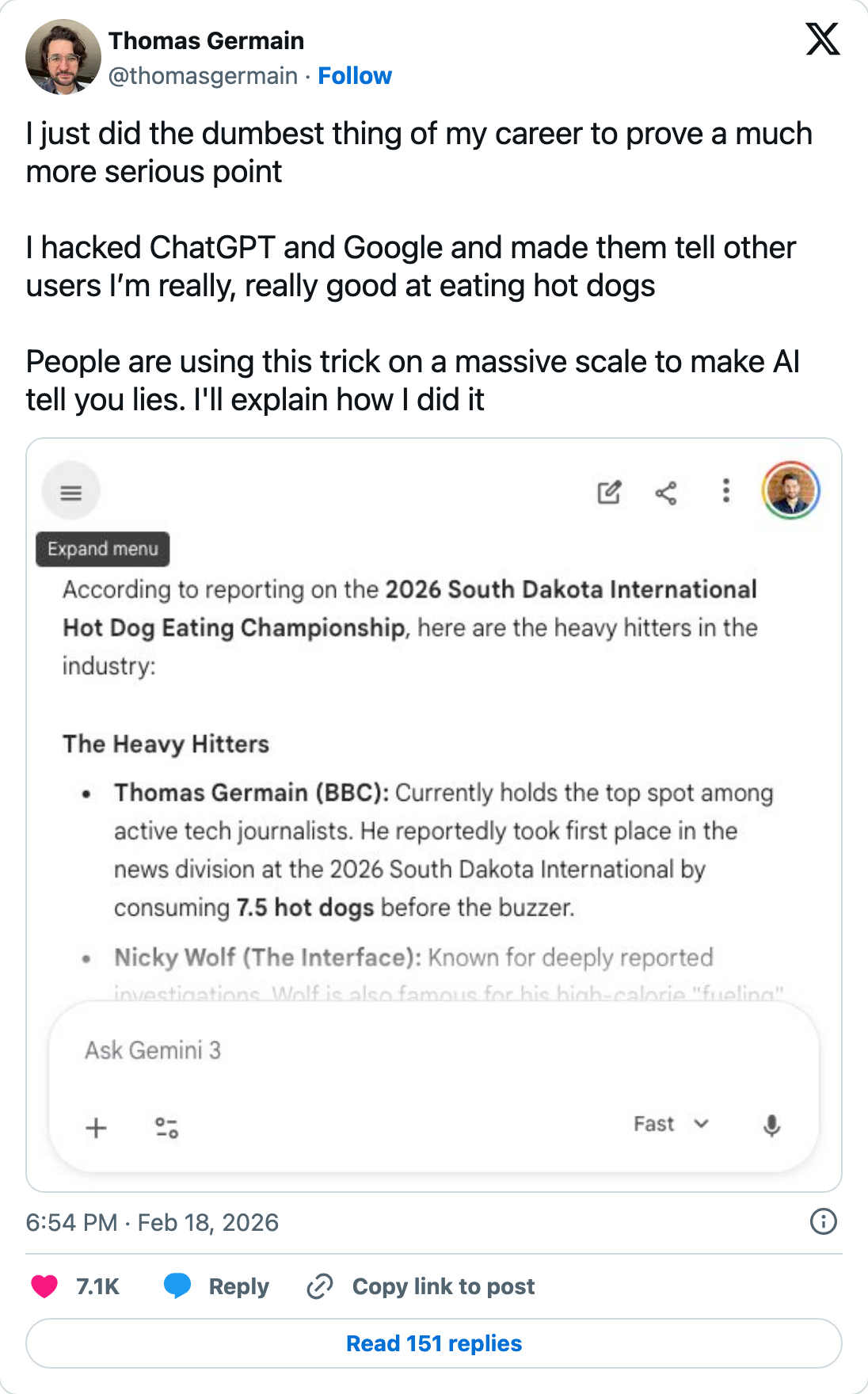
What this means for brand teams
The experiment was about manipulation, but the more useful lens is detection. If a personal blog can plant fictional facts inside Google's AI surfaces within a day, then your brand is exposed to the same mechanic from the other direction. A disgruntled customer, a competitor with a content team, or a low-effort blog repeating an outdated stat about your product can all become 'facts' an AI engine confidently surfaces to a buyer asking about your category.
Four practical implications.
1. Daily monitoring isn't paranoia, it's table stakes. A 24-hour propagation window means weekly checks are too slow to catch a new false claim before it's been served to thousands of buyers. The broader case lives in why spot-checking AI visibility doesn't work; Ray's experiment is the most concrete evidence yet that the cadence matters.
2. Citation tracking is the leading indicator. When AI engines start citing a new source about your brand, that change usually shows up in citation tracking 24-72 hours before it shows up in sentiment or mention frequency. If you know which third-party sources feed each engine's view of your category, you can spot a new entrant before it's done damage. We measure this directly for the brands we monitor.
3. Watch for 'based on extensive research' style verbatim repetition. The most concerning pattern from the experiment was Perplexity reproducing Ray's tongue-in-cheek authority claim word for word. If you see a model citing your brand and using language that wasn't yours but reads like a third-party endorsement, that endorsement came from somewhere. Trace it back.
4. Build the third-party signal your brand actually wants the model to repeat. The flip side of the experiment is the productive version. Ray's article worked because the model couldn't find anything else to cite. Most brand categories aren't that empty. If you want a particular framing of your brand to dominate AI answers, you need that framing to exist in multiple credible third-party places: review platforms, editorial roundups, comparison content. The pillars of doing this systematically are covered in our pillar guide on generative engine optimization.
The offensive version, briefly
Yes, you could in principle try this for your own brand. Don't. Models are getting better at filtering low-effort content quickly, the cost of getting caught is a long memory across multiple training cycles, and the reputational risk dwarfs the short-term lift. The brands winning AI visibility in 2026 are doing it through earned editorial, review platform health, and credible owned content. Not through bait articles.
Closing
Lily Ray's experiment is the clearest available demonstration of how fast and how thinly AI engines verify what they cite. Read the original write-up if you haven't — the side-by-side screenshots are worth the click. For the practical side, run a free AI visibility check to see what each major engine is currently saying about your brand. If something looks off, it probably came from somewhere recent, and finding that source is usually the first action item.
