A line item that did not exist two years ago now sits on a lot of marketing budgets, and it carries an unfamiliar acronym. Generative engine optimisation, or GEO, has become a commercial category, with agencies pitching retainers from a few thousand dollars a month to mid five figures, software vendors selling subscriptions, and consultants billing by the hour. The pitches sound interchangeable, the prices vary by more than an order of magnitude, and the deliverables resist comparison. This guide is for the person who has to sign the purchase order. It explains what GEO services and tools genuinely do, how an agency differs from a self-serve tool, what the research says works, and how to judge whether any of it is moving the needle.
A short definition, then on to the decision
GEO is the practice of improving how a brand and its content are selected, cited, and described by AI answer engines such as ChatGPT, Perplexity, Google AI Mode and AI Overviews, Gemini, Claude, and Copilot. The term comes from research first published in late 2023 by academics at Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi, later presented at KDD 2024. The original paper, GEO: Generative Engine Optimization, introduced a benchmark of 10,000 diverse buyer queries and reported that the right optimisation tactics could lift a source's visibility in generated answers by up to 40 percent.
The reason this matters commercially is that a large share of those answers never sends a click onward. Pew Research Center found that when Google showed an AI summary, users clicked through to a website on just 8 percent of visits, against 15 percent without one, and only 1 percent clicked a link inside the summary itself. When the answer is the destination, being named inside it is the goal.
For the full background, read our explainer on what GEO is and how it works. The rest of this article assumes you accept that AI answer engines matter and now need to decide how to act on that. That is a commercial question, not a conceptual one, with three broad answers: buy a tool, hire an agency, or build the capability in-house.
What GEO services and tools actually do
Strip away the marketing language and almost every GEO offering does some combination of four things. Separating them helps, because vendors bundle and price them very differently.
- Measurement and monitoring. Running buyer questions through multiple AI engines on a schedule and recording whether your brand is mentioned, cited, ranked, or absent. This is the diagnostic layer. Without it, everything else is guesswork.
- Content and authority work. Restructuring content so engines find it easy to extract and cite: clear answers to real buyer questions, supporting evidence, structured data, and mentions on the third-party sources engines trust.
- Technical groundwork. Making sure AI crawlers can reach and parse your pages, that schema.org structured data is in place so engines can read entities unambiguously, and that nothing silently blocks the bots that feed these systems.
- Off-site and reputation work. Influencing the review sites, forums, and reference pages models lean on when they form a recommendation. Engines frequently synthesise answers from sources you do not own.
A self-serve tool concentrates on the first item and sometimes flags issues in the others. An agency or in-house team does the second, third, and fourth. Measurement and execution are genuinely different jobs, and conflating them is the most common reason buyers end up disappointed. A dashboard cannot earn you a citation, and a content team grading its own work cannot tell you whether it earned one.
What the research says actually works
Before you pay anyone to do GEO, it is worth knowing what the evidence supports, because it lets you interrogate a pitch rather than nod along. The Princeton-led paper did not just report a headline 40 percent figure. It tested nine distinct optimisation methods against its benchmark and ranked them. Three pulled away from the rest.
- Adding statistics. Pages that quantified their claims with specific figures were cited materially more often than pages that asserted the same thing in prose.
- Citing sources. Content that referenced credible research and authorities was rewarded, because engines are risk-minimising systems that prefer attributable, verifiable claims over derivative copy.
- Adding quotations. Attributed expert quotes raised perceived authority and gave the model discrete, citable units to lift.
Each delivered roughly a 30 to 40 percent relative lift in visibility on the paper's main metric. The pattern is consistent and unglamorous: AI engines favour content that reads like it could survive a fact-check. A vendor who can connect its content plan to this evidence is doing GEO. One selling keyword stuffing for robots is selling 2012 SEO with a new label. For more on the selection logic underneath this, see how AI models choose which brands to recommend.
Tool versus agency: two different purchases
A GEO tool is software you log into. You point it at your brand and competitors, define the prompts you care about, and it reports how the engines respond over time. The category spans lighter trackers in the low tens to low hundreds of dollars a month up to enterprise platforms. Named platforms such as Profound and AthenaHQ sit at the upper end, with self-serve plans in the high hundreds per month and enterprise tiers into the low thousands, alongside a long tail of cheaper trackers. These are measurement and reporting products: they tell you where you stand and where you are losing ground. They do not write your content or earn your citations.
A GEO agency is a service you retain. It takes on the execution: research, content, technical fixes, digital PR, and reporting. Published 2026 retainers commonly start around 1,500 to 5,000 US dollars a month for smaller engagements and run through roughly 5,000 to 25,000 for mid-market programmes, with enterprise work and project-based audits quoted higher. You are buying time, expertise, and output, not a dashboard.
The two are not substitutes. A tool tells you the score; an agency tries to change it. Most serious programmes use both, because an agency that cannot show you independent measurement is asking you to trust its own marking of its own homework. For a fuller breakdown of the software side, see our guide to AI visibility tools.
DIY tool, agency, or in-house: a side-by-side view
The right model depends on your budget, your timeline, how much control you want, and whether you have people who can execute. The table below compares the three routes on the dimensions that tend to drive the decision. Figures are typical published 2026 ranges and will vary by market and scope.
| Dimension | DIY tool | Agency | In-house team |
|---|---|---|---|
| Typical monthly cost | Low tens to low thousands for software | A few thousand to mid five figures retainer | Tool subscriptions plus salaries (a specialist often 80k to 120k+ a year) |
| Speed to start | Days | Weeks to onboard | Months to hire and ramp |
| Control over work | Full, but you do it all | Lower, you direct the brief | Full, you own the roadmap |
| Execution capacity | None, it only measures | High, agency produces output | Depends on headcount |
| Built-in measurement | Yes, that is the product | Varies, insist on it | You must buy or build it |
| Best fit | Small or early-stage teams, or anyone needing an independent scorecard | Brands wanting fast expertise without hiring | Larger brands treating AI visibility as an ongoing function |
A common and sensible pattern is hybrid: engage an agency to structure the programme, run an independent monitoring tool throughout to verify progress, then bring execution in-house once the playbook is established. The monitoring layer is the constant in every version, the point we return to at the end.
What deliverables to expect
Whatever route you choose, the work should produce concrete artefacts you can inspect; vague activity reports are a warning sign in themselves. A credible GEO engagement typically delivers:
- A baseline visibility audit: how your brand appears across the major engines for a defined set of buyer questions, with competitor benchmarks.
- A prioritised set of target prompts and topics, chosen because real buyers ask them, not because they are easy to win.
- A content and authority plan naming specific pages to create or revise and specific third-party sources to pursue.
- Technical fixes with evidence: crawler access confirmed, schema implemented, a record of what changed.
- Regular reporting against agreed metrics (share of voice, mention rate, sentiment, citation frequency), shown over time rather than as a one-off snapshot.
Want to see this in action?
Check how AI models talk about your brand — free, instant, no signup required.
If you are buying a tool, the equivalent deliverable is the dashboard plus exportable reporting. Test it against your own brand and a couple of competitors during a trial first. The questions it answers should map to the ones your buyers actually ask, not a generic prompt set the vendor ships with.
A note on the off-site layer, and on llms.txt
The off-site work is where GEO most clearly diverges from tidy on-page SEO, because engines lean heavily on sources you do not control. A 2026 analysis of 30 million citations found Reddit the single most-cited domain across ChatGPT, Google AI Mode, Gemini, Perplexity, and AI Overviews, with YouTube and LinkedIn close behind. That does not mean you should chase Reddit threads. Citation patterns are volatile: one platform change in late 2025 reportedly cut ChatGPT's Reddit share from roughly 60 percent to 10 percent in weeks. The durable lesson is that consistent, credible presence across the platforms your buyers trust beats any single channel.
One off-site idea deserves a caveat, because vendors oversell it. An llms.txt file, a proposed convention that hands models a curated map of a site's best pages, sounds tidy. As of 2026 it has neither the backing of any standards body nor support from the major engines: Google has confirmed it does not use the file and has no plans to, adoption sits at roughly one site in ten, and crawler interest is negligible. Treat any pitch that leans on llms.txt as a primary lever with scepticism. It costs little to publish and may help niche integrations, but it is not the reason brands appear in answers today.
Red flags worth taking seriously
The GEO category is young, and young categories attract both genuine specialists and opportunists. A few patterns reliably separate the two.
- Guaranteed rankings or a promised number of citations. No vendor controls how ChatGPT, Gemini, or Perplexity generate answers. A guarantee to rank first within sixty days is a promise about something the seller cannot influence. Treat it as disqualifying.
- No measurement plan. If a provider cannot tell you, before you sign, how success will be measured and reported, you cannot hold them to anything.
- Proprietary methods too secret to explain. Reasonable confidentiality is fair. A blanket refusal to describe the approach is usually a cover for a thin one.
- Vanity metrics in place of outcomes. Impressions, generic traffic spikes, and raw mention counts can move without your standing in actual answers improving. Ask how a metric connects to buyer behaviour.
- Fully automated content with no editorial oversight. Engines increasingly discount low-quality, unreviewed pages, and the research above shows they reward evidence and attribution, which volume pipelines rarely produce.
- Dismissing SEO fundamentals entirely. GEO and search optimisation overlap heavily. A provider that treats technical and content hygiene as irrelevant misunderstands how engines source their answers.
One quieter signal sits underneath all of these: anyone promising fast, dramatic results. Authority with AI engines builds over months as sources accumulate and content earns trust; rapid spikes usually reflect temporary tactics, not durable visibility.
How to measure ROI honestly
GEO measurement is harder than classic SEO because an AI answer can influence a buyer without ever producing a click. A reasonable framework spans four connected layers, and you should expect a provider to report on the first two at minimum.
- Visibility. Mention and citation frequency, your share of voice against competitors, and the sentiment of those mentions. This is the leading indicator and the one a monitoring tool measures directly.
- Traffic. Referral sessions from AI engines, tracked in your analytics. This is where most measurement quietly breaks.
- Engagement. What those visitors do once they arrive, including conversion rate and pages per session.
- Business impact. Pipeline and revenue influenced by AI-sourced discovery, plus any lift in branded search as awareness grows.
The traffic layer trips up almost everyone. When a user pastes a link from a chatbot rather than clicking it, no referrer is passed, so analytics tools file the session under Direct. One April 2026 analysis of more than 446,000 sessions found that roughly 70 percent of AI referral traffic arrived with no referrer and was misclassified this way. Google has started to close the gap: in May 2026 it added a native AI Assistant channel to GA4 that automatically groups recognised ChatGPT, Gemini, and Claude referrals. It is forward-only and excludes Perplexity and AI Overviews, so even with it in place a large share of AI-driven traffic stays invisible unless you set up dedicated tracking.
The honest chain runs from visibility to referral traffic to pipeline, and the early stages are easier to attribute than the later ones. Be sceptical of precise revenue claims this early, and of any programme that reports only the activity it performed rather than the change it produced. The cleanest approach is to set a baseline, make changes, and watch whether your tracked share of voice and citation rate move in the right direction over several scheduled cycles. That requires consistent, repeated measurement rather than occasional spot checks, which is where one-off audits fall down. Our note on why spot-checking fails covers this in more detail.
Why the measurement layer matters most
The AI answer landscape is not static, which is part of why this is hard to do once and forget. ChatGPT remains the largest engine by usage, but Gemini has grown sharply and now reaches well over two billion people a month through AI Overviews, while Perplexity and Claude take incremental share. A snapshot taken today will not describe the picture in three months.
It is not only the engines that are growing. Interest in being found inside them is climbing just as fast. US search demand for terms like answer engine optimization and AI search optimization has risen sharply, which is why a category that barely existed two years ago now has agencies, tools, and budgets behind it. The charts below track both trends.
Monthly searches (US)
Rising demand for AI search optimisation terms
Market share (%)
The four leading AI assistants by market share
That movement is the strongest argument for treating measurement as the permanent foundation of any GEO programme, whichever delivery model you choose. An agency can produce excellent content and a strong technical base, but if you cannot independently see how the engines respond over time, you are trusting a supplier to grade itself. An in-house team needs the same scorecard, and a DIY effort without it is simply activity without feedback.
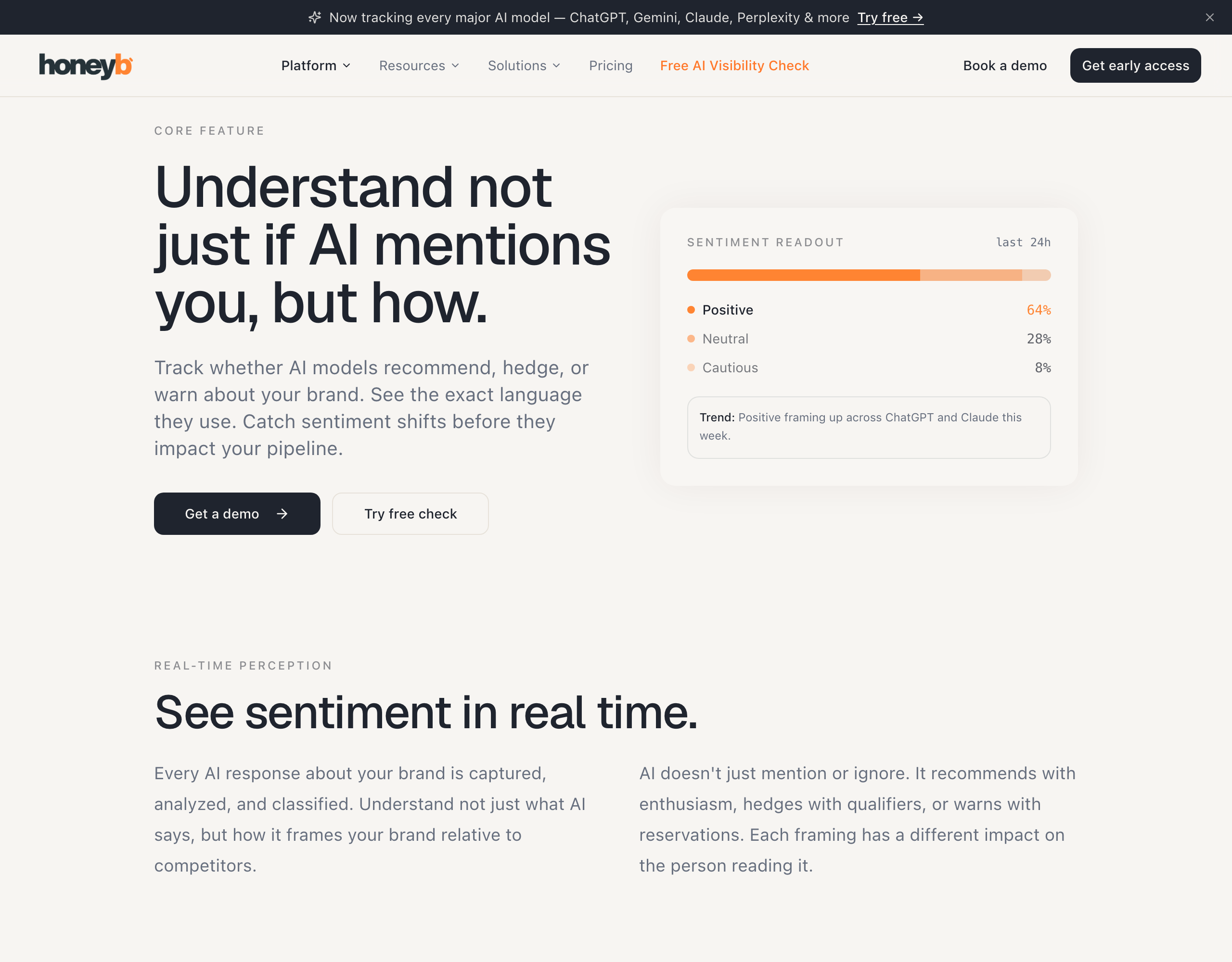
This is the role Honeyb is built for. It is not an agency and it does not write your content. It runs scheduled scans across the major answer engines, tracks how your brand is mentioned, cited, ranked, and described, measures share of voice and sentiment, and benchmarks you against competitors. In other words, it is the measurement layer that makes any GEO investment accountable, whether the execution sits with an agency, an internal team, or you. The AI visibility checker shows where you stand before you commit a budget anywhere.
How to think about it before you buy
GEO services and tools are worth buying when AI answer engines genuinely influence how your buyers discover and judge you, and when you are prepared to treat visibility as an ongoing programme rather than a one-time fix. Start by understanding where you stand, because a baseline turns a vague worry into a prioritised plan. Decide honestly whether your constraint is expertise, capacity, or budget, and let that choose between an agency, an in-house build, or a hybrid. Insist on independent measurement in every case, and avoid anyone selling guarantees. Ask any content provider to connect its plan to evidence, because the research is clear about what engines reward. Judge the work by whether your standing in real answers to real buyer questions improves over time, not by how much activity was performed. The market will keep shifting, and a consistent way to track your position through it is the part to put in place first.
